

Artificial Intelligence (AI) is a rapidly evolving field that has gained significant attention in recent years. In this blog post, we will explore the fundamental concepts of AI, with a special focus on Machine Learning and Neural Networks. This overview aims to provide a basic understanding of AI for individuals without background on the topic and serves as a foundation for further exploration into the fascinating world of AI.
- What is Artificial Intelligence?
Artificial Intelligence refers to the development of computer systems that can perform tasks that typically require human intelligence. These tasks include problem-solving, decision-making, speech recognition, and image processing. AI systems aim to mimic human intelligence by utilizing algorithms and models to process and analyze data.
- What is Machine Learning?
Machine Learning is a subfield of AI that focuses on algorithms and models that enable computers to learn from data and make predictions or decisions without being explicitly programmed. It involves training a model on a dataset to identify patterns and relationships, allowing it to generalize and make accurate predictions on unseen data.

Typical workflow when using Machine Learning to solve a problem
- Datasets Essentials
Datasets are collections of data used to train and evaluate machine learning models. High-quality datasets are essential for the success of AI models. They should be diverse, representative of the problem domain, and, depending on the Machine Learning algorithm using them, contain a sufficient number of labeled examples to facilitate learning.
- Types of Machine Learning
There are three primary types of Machine Learning: supervised learning, unsupervised learning, and reinforcement learning.
- In supervised learning, models learn from labeled examples to make predictions or classify data.
- Unsupervised learning involves finding patterns or structures in unlabeled data. Self-supervised learning is a related case, where structure in the data is used to obtain a supervisory signal.
- Semi-supervised learning, an additional type sitting somewhat in between both of them, combines labeled and unlabeled data to enhance model performance.
- Reinforcement learning focuses on training an agent to interact with an environment and learn through rewards or punishments.
- What are Neural Networks?
Neural Networks are machine learning models inspired by the human brain. By leveraging the collective power of interconnected neurons and layers, Neural Networks can effectively learn from data and solve a wide range of complex problems, including image recognition, natural language processing, and decision-making tasks.
An artificial neuron is a fundamental unit in Neural Networks responsible for processing and transmitting information. While it differs from the neurons in the human brain, which rely on chemical reactions rather than mathematical operations, the resemblance lies in their shared ability to activate with variable intensity according to the received data. Each artificial neuron takes in multiple inputs, calculates the weighted sum, and applies an activation function to produce an output.
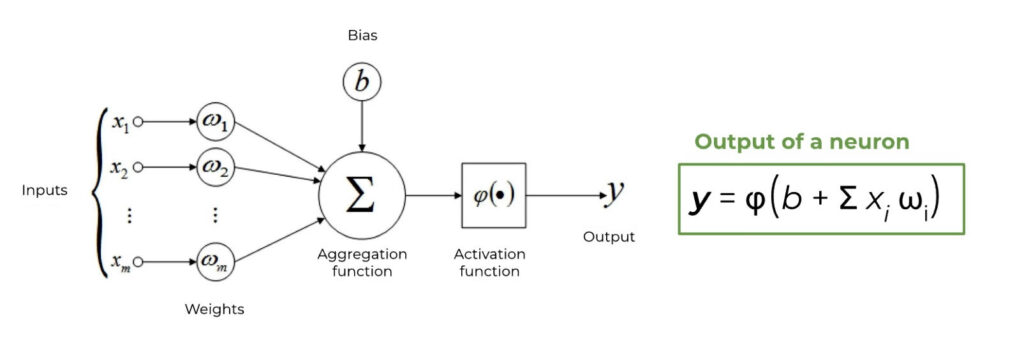
An artificial neuron, basic unit of Neural Networks
Activation and Output: The inputs, weighted by their corresponding weights, are summed together. This summation is followed by the application of an activation function. The activation function introduces non-linearity, enabling the neuron to model complex relationships in the data. Common activation functions include sigmoid, ReLU, and tanh. The output of a neuron is the result of the activation function applied to the weighted sum of inputs. This output then becomes an input for other neurons in the subsequent layers of the Neural Network.
Layers and Connections: Within Neural Networks neurons are organized into layers. The input layer receives initial data, and the output layer produces the final prediction of the network. Hidden layers in between extract increasingly abstract and complex features from the data. Neurons in adjacent layers are connected by edges, with each connection having an associated weight.
Deep Learning is a subfield of Machine Learning which utilizes Neural Networks with large numbers of layers to learn hierarchical representations of data.
Neural networks may include various types of layers, such as convolutional layers for feature extraction in image data, fully connected layers for general pattern recognition, and recurrent layers for sequential data analysis. A single network usually contains more than one of these types of layers.
Learning and Training: During training, Neural Networks learn by adjusting the weights and biases of connections between neurons to optimize their performance on a given task. This process involves four steps:
1- Forward pass: Input data is fed to the network, propagating forward from the input layer through hidden layers to generate predictions.
2- Loss computation: The performance of the network is measured using a loss function. This function will depend on the task the network is used for, and the lower the value, the better the performance. In the case of supervised learning the loss function will measure the difference between the predicted outputs and the actual labels.
3- Backpropagation: Gradients are calculated by propagating the loss backward through the network, layer by layer, using the chain rule technique. This process determines the impact of each parameter on the overall loss.
4- Loss optimization: Optimization algorithms adjust the parameters of the network iteratively based on the computed gradients. The goal is to minimize the loss and improve the network’s performance. There are many commonly used strategies, usually called optimizers, such as gradient descent or Adam.
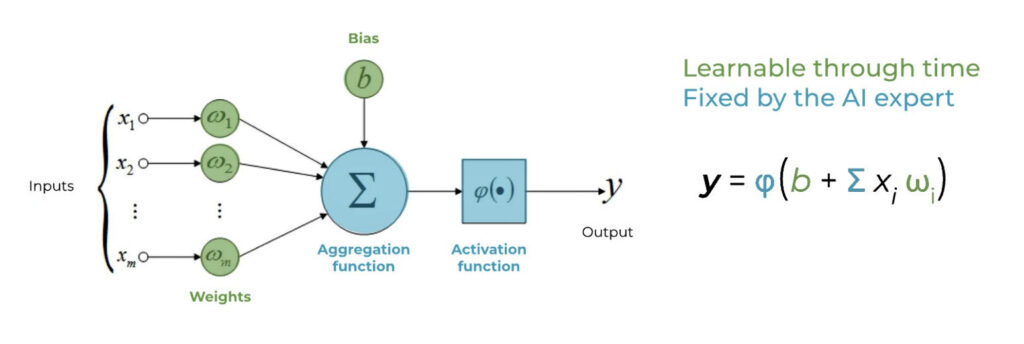
Learnable and fixed components of an artificial neuron
Overfitting and Underfitting: Overfitting and underfitting are common challenges in Machine Learning.
Overfitting occurs when a model is too complex for the data used to train it. In these cases, it performs well on this training data but fails to generalize to new, unseen data.
Underfitting, on the other hand, happens when a model is too simple and fails to capture the underlying patterns in the data.
Balancing these two extremes is crucial to achieve optimal model performance.
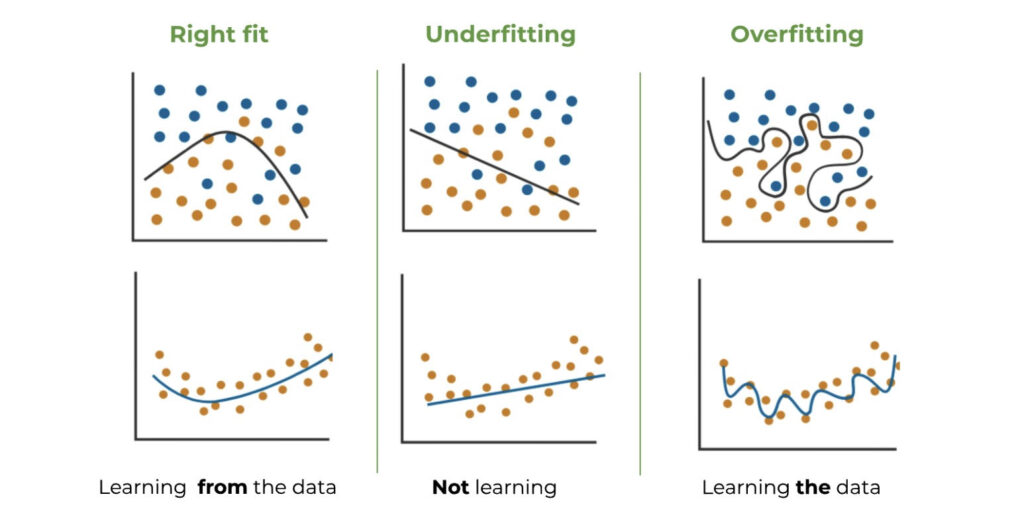
- How do Neural Networks perform?
Models are trained by optimizing a loss function, but these are usually non-intuitive to understand how a model performs, instead metrics are used to evaluate their performance. The reason why we do not use metrics to train models is that a loss function needs to meet some mathematical properties for backpropagation to work that most metrics do not meet. Additionally, it is vital that losses and metrics are as closely related as possible, so that as the loss decreases, the metrics improve.
Depending on the specific task there are different ways to evaluate an AI model, and usually the more complex the task the more complex the metric. For example, the Cross-Entropy loss, commonly used on classification problems, measures the difference between the probability distributions of the predictions and the labels. Instead of this opaque value, metrics such as accuracy, recall or precision are better suited to judge the performance of a model.
It is important to note that not all tasks have globally accepted metrics. Certain specialized tasks, like keypoint detection or generative models, may require task-specific metrics or evaluation criteria. Researchers and practitioners often develop custom metrics to assess the performance of models in these unique contexts.


