


Computer Vision is a dynamic Artificial Intelligence field that encompasses the study and development of algorithms and techniques to enable computers to interpret and understand visual information. In this blog post, we will delve into the fundamentals of Computer Vision, shedding light on its key concepts and tasks.
- What is Computer Vision?
Computer Vision refers to the field of study focused on empowering computers to gain visual perception and understanding from digital images or video. By leveraging sophisticated algorithms and models, Computer Vision enables machines to interpret and extract meaningful information from visual data, mimicking human visual cognition.
- How a Computer Interprets an Image
When computers analyze images, they perceive them as numerical data represented by pixels. The pixel values encode color and intensity information, allowing for mathematical processing to extract essential features and patterns. Depending on whether the image is grayscale or color, it can be converted into a single 2D matrix or three separate 2D matrices, respectively. These matrices serve as the foundation for subsequent analysis and comprehension of the visual content.
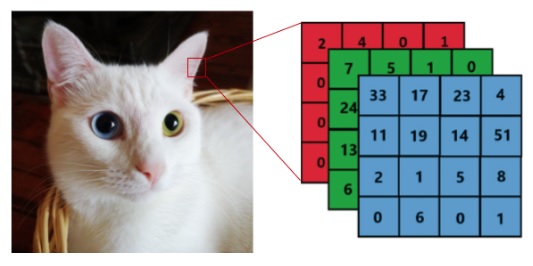
Matrix representation of a color image

Matrix representation of an one-dimensional image
- Computer Vision Tasks
Computer Vision encompasses tasks such as image classification, object detection, image segmentation, image generation, and Optical Character Recognition (OCR), among others. These tasks involve extracting knowledge and insights from visual data. Image classification assigns labels to images, object detection identifies and localizes objects, and image segmentation partitions images into meaningful regions. Image generation creates new images based on learned patterns, while OCR recognizes and extracts text from images. Together, these tasks contribute to a comprehensive understanding and analysis of visual content.
- Convolutional Neural Networks
The convolution operation plays a crucial role in Computer Vision, being the basic building block of Convolutional Neural Networks (CNNs). It involves sliding a small filter, also known as kernel, over an input image to extract local patterns and features. Convolutional Layers in Neural Networks utilize this technique, employing multiple filters to detect visual patterns at different spatial locations.
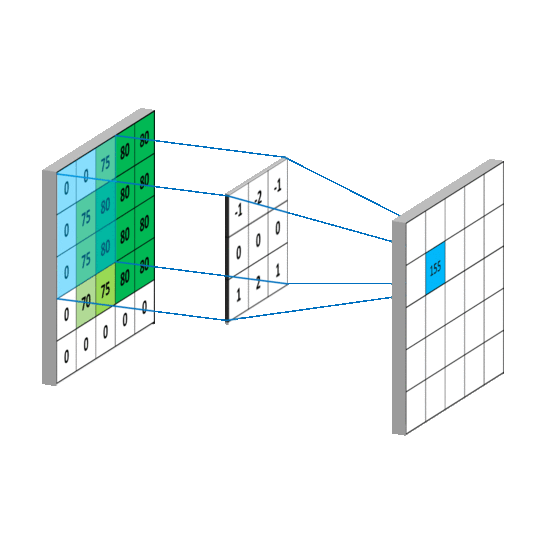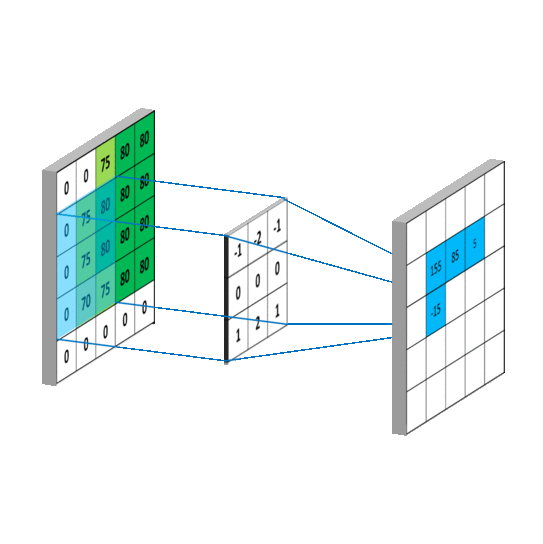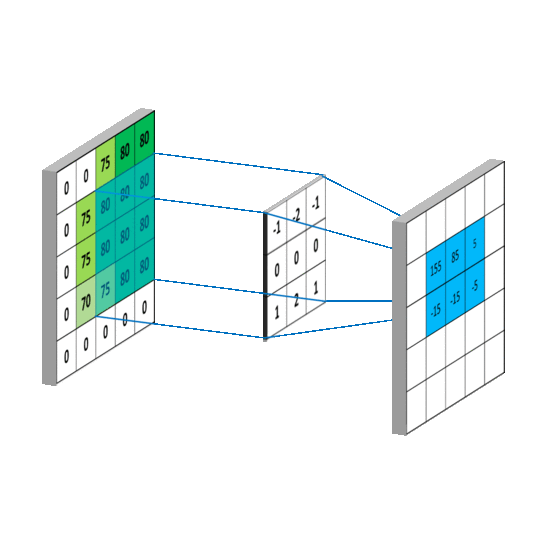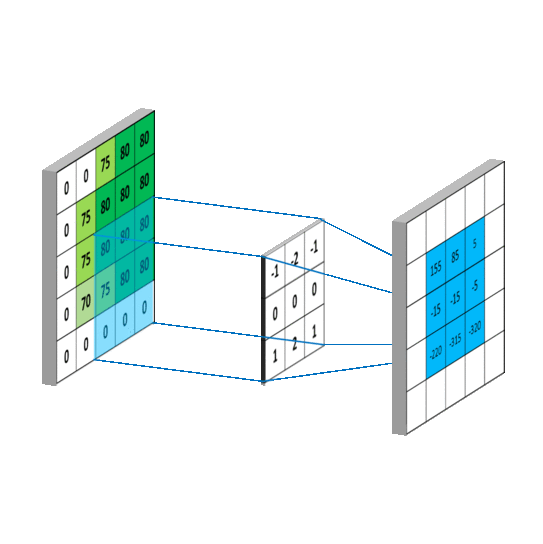
Convolutional filter applied to an one-dimensional image
In Computer Vision, the learning process involves adapting the weights of the network to capture local dependencies effectively and extract meaningful features from input images. In CNNs, these weights correspond to the values within the convolutional filters. Each element within the filter represents a weight, which is adjusted during training to learn specific visual patterns. By learning these filter weights, CNNs can automatically extract relevant features, such as edges, textures, or more complex structures, allowing for effective image understanding and analysis.
Apart from Convolutional Layers, CNNs also incorporate other essential layers. Pooling layers downsample feature maps, reducing spatial dimensions while preserving crucial information. Fully Connected layers connect all neurons in one layer to every neuron in the subsequent layer, facilitating high-level feature representation and final predictions.
- Basic Structure of a CNN
CNNs typically consist of three main components: the feature learning backbone, feature enhancement neck, and prediction heads. The feature learning backbone performs initial feature extraction from the input image, gradually capturing low-level to high-level visual features. The feature enhancement neck refines and enhances these features, enabling better discrimination and generalization. Finally, the prediction heads generate the desired outputs, such as class labels or object bounding boxes.
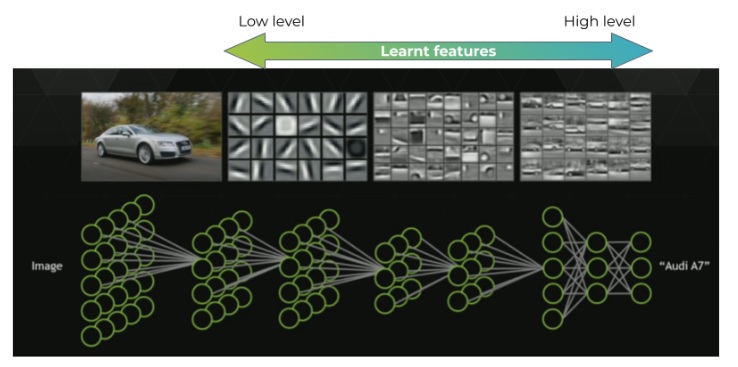
- How does a CNN “see” an Image? Low-Level and High-Level Features
A CNN sees an image by learning and extracting both low-level and high-level features. Low-level features, such as edges, corners, and textures, are captured in early layers, providing foundational visual cues. As the network deepens, high-level features representing more complex patterns and semantic information emerge. These features allow CNNs to make increasingly sophisticated interpretations and predictions.
- Computer Vision and NLP: Similarities
Although Computer Vision and Natural Language Processing (NLP) are distinct fields, they share similarities. Both fields rely on Deep Learning techniques to extract meaningful representations from raw data. In Computer Vision, visual features are extracted from images, while in NLP, linguistic features are derived from text. Both fields benefit from similar Deep Learning architectures, Transfer Learning techniques, and advanced models such as transformers.
- Transfer Learning: Leveraging Pre-Trained Networks for Enhanced Performance
Transfer Learning has emerged as a powerful technique in Computer Vision, revolutionizing the field and accelerating model development. It involves utilizing pre-trained neural networks, trained on large-scale datasets, as a starting point to benefit new related tasks. Transfer Learning has become a key instrument in overcoming limitations arising from data scarcity and computational constraints. It enables the use of Deep Learning models even with limited amounts of task-specific data, which is particularly crucial for scenarios where obtaining extensive labeled datasets is challenging or time-consuming. The other main benefit of Transfer Learning is that it significantly reduces the computational burden, as pre-trained models serve as powerful starting points, reducing training time and resource requirements.
Pre-trained Networks: Pre-trained networks have already learned rich representations of visual features, after training on massive datasets, such as ImageNet. By reusing their learned features, the time-consuming process of training a model from scratch on large-scale datasets can be overcome.
ImageNet is an extensive dataset with millions of labeled images and models trained on it possessing a remarkable ability to capture and generalize visual features, making them highly suitable for a wide range of vision tasks. The models pre-trained on huge datasets such as ImageNet provide a robust foundation for subsequent specialized tasks.
Fine-tuning: While pre-trained networks provide valuable initial features, fine-tuning is often necessary to adapt the model to the specific task at hand. Fine-tuning involves re-training the pre-trained network on task-specific data, allowing it to adjust its learned features to better align with the target domain while retaining the general knowledge gained from pre-training.
The continuous advancements in Transfer Learning techniques promise to propel the field of Computer Vision further, enabling the development of robust and accurate models across a wide range of visual tasks.
